Free and open AI-based cloud mask for Sentinel-2
Asking a person on the street ‘what is a cloud mask and why would one need it’, you would probably receive more questions than answers. Yet people who have worked with EO data for at least a year, or, even better, who have tried to program an automatic classifier, know exactly what we are talking about.
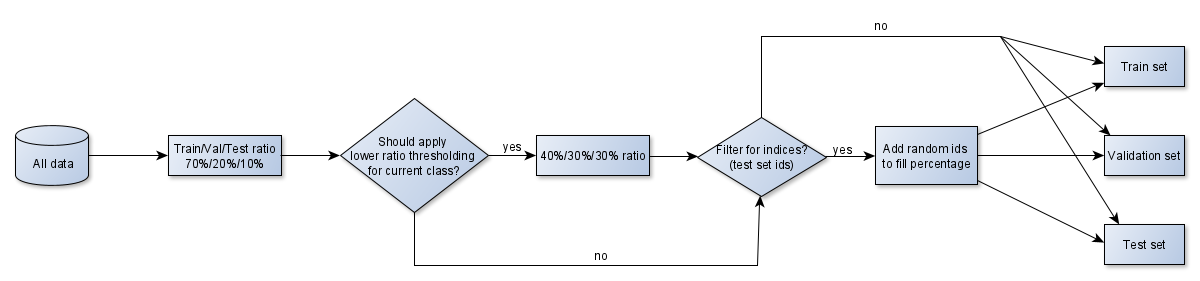
Sentinel-2 is a beautiful European data factory, producing tons of valuable imagery every day. Its full potential is yet to be exploited. The first Sentinel-2 satellite was launched in 2015 and after launching the second satellite (2B) the system reached its full data production capacity in the second half of 2017. One of the factors limiting the usage of Sentinel-2 data is clouds. There is a need for an accurate mask for separating the clear pixels from the corrupted ones. Figure 1 illustrates it well – not only the cloud covered areas are unusable for great majority of EO applications, but also the cloud shadows cause trouble. If you run e.g. a crop classification algorithm on these regions you cannot expect an adequate result.

While Sentinel-2 system, functioning as a data factory, is beautiful and undeniably a huge game changer, then the official Sen2cor cloud mask incorporated to the L2A data products can be insufficient in terms of accuracy when used in fully automatic processing chains. The issues rise with underestimating the cloud shadows and small fragmented clouds. While feeding an operational processing chain (such as the grassland mowing detection system of KZ) with this data a lot of corrupted pixels are passed through, deteriorating the accuracy of the end result. In practice we have ended up with aggressive outer buffering and few other post-processing steps to reduce the errors. But obviously these are all just work-arounds without solving the underlying problem. The cloud mask itself, out-of-the-box, should be accurate enough without thinking about it during the work processes.
When digging deeper, you find that the Sen2cor cloud mask processor has a rule-based thresholding decision tree with some post-processing steps (e.g. morphological filtering to reduce the noise). On one hand it is impressive how accurate results this decision tree is able to produce in a global scale, but after the revolution of AI and deep learning one knows that the same task can be solved much better with a different – more modern design.
Leaving the Sen2cor cloud mask as it is, the proposal of KappaZeta was convincing enough that we were given a chance to develop an AI-based Sentinel-2 cloud mask for ESA and we are very grateful for it.
Which other cloud masks are out there?
Firstly, we would like to outline how import is to develop open source cloud masks. There are a few privately developed cloud masks, raising the first question about accuracy figures. If these details are not public, it is also hard to assess how good the offered product really is and that raises many other questions. Furthermore, this adds to the unnecessary amount of time spent on something that could be shared openly, reducing duplication, and contributing to improved products. Therefore, everybody would win time-wise and quality-wise from more open approach and sharing. This is what we believe in and hope that more and more companies over time will come to the same conclusion.
One of the best open source cloud masks is probably s2cloudless by Sinergise. Find more information from here, here and here.
There is just one thing we would like to question and open for discussion. They write that: “We believe that machine learning algorithms which can take into account the context such as semantic segmentation using convolutional neural networks (see this preprint for overview) will ultimately achieve the best results among single-scene cloud detection algorithms. However, due to the high computational complexity of such models and related costs they are not yet used in large scale production.” So CNNs are great, but too heavy to be practical? Let us put this claim in doubt, at least in 2020. One thing is CNN model fitting, which for a complex model can be computationally expensive, that is true. But the other thing is running a prediction with a pre-trained model. This is much cheaper – and this is what you need to do when you put a CNN into production.
One of the best research papers on using deep learning for cloud masking is probably by DLR. We are taking this as one of the starting points for our development. They claim higher accuracies than Fmask (which is roughly on the same level with Sen2Cor) at a reasonable computational cost (2.8 s/Mpix on a NVIDIA M4000 GPU).
There are also several CNN-based cloud masking research papers by the University of Valencia. E.g. by Mateo-García and Gómez-Chova (2018) and Mateo-García, Gómez-Chova and Camps-Valls (2017).
All in all – deep learning as a universal mimicking machine has proven to be at least as accurate in recognizing objects from images and segmenting them semantically as human interpreters. Deep learning has been proven in various domains with image interpretation, speech recognition and, text translation. Computer Vision, which focuses particularly on digital images and videos, has enormous success in medical field, where data labelling is an expensive procedure or rapidly developing autonomous driving cars field, where huge amount of data should be processed in real time. There is every reason to believe that it will excel also in detecting clouds and cloud-shadows from satellite imagery. What determines the success is the quality and variety of the model fitting reference data set.
We believe that cloud masking is such an universal pre-processing step for satellite imagery that sooner or later someone will develop an open source deep learning cloud mask and all the closed source cloud masks become obsolete. Let us then try to be among the first and help the community further.
How?
The goal of the project is to develop the most accurate cloud mask for Sentinel-2. We know it is going to be hard and to avoid going crazy by trying to solve everything at once, we are limiting the scope of the project. We concentrate on Northern European terrestrial summer season conditions. With Northern Europe we mean the area north from the Alps, which has relatively similar nature and land cover. Summer season means the vegetative season – from April to October. We start from terrestrial conditions (with all due respect to the marine researchers), because we believe it has higher impact for developing operational services that make clients happy, for example in the agricultural and forestry sectors.
Everyone, who has worked on machine learning projects, know that the most critical factor for success is the quality and variety of input data. In our case it is the labelled Sentinel-2 imagery following the classification schema agreed in CMIX. Eventually each pixel should have a label, one out of four: 1) clear, 2) cloud, 3) semi-transparent cloud, 4) cloud shadow. For labelling we are using CVAT with a few scripts for automation and thanks to the hard work of our intern Fariha we have already labelled more than 1500 Sentinel-2 cropped 512x512 pixels tiles. The work goes on to have a large and accurate reference set for CNN model fitting.

To be more effective, there are several machine learning techniques we are going to apply:
1) Active
learning. To select only the tiles and
pixels, which have the highest impact for increasing the accuracy of the model.
Labelling is a time-consuming process, and it is critical to do only work that
matters.
2) Transfer
learning. The idea is to use all possible
open sources labelled Sentinel-2 images to train the network and then fine-tune
it on our smaller focused dataset.
The initial literature review is completed and we plan to start with applying U-Net on our existing labelled dataset. We still have many open questions, e.g. should we use one of the rule-based masks as an input feature; is the improvement worth the fear that the network can possibly capture the same errors; to what extent we can augment existing features in terms of brightness and angles; can certain calculated S2 coefficients help the network, such as NDVI, NDWI etc?
Last, but not least, it is an open source project. All our results, final software and source code will be freely and openly distributed in GitHub. Openness and accessibility of our software should directly translate into greater usage. We are also intending to learn from the community and take advantage of the existing open source projects and labelled cloud mask reference data sets.
If you have any good suggestions how we could improve our cloud mask or be aware of some parallel developments for cooperation, please let us know. Our project runs from October 2020 to September 2021.
Further information:
Marharyta Domnich
marharyta.dekret@kappazeta.ee