
Everyone who has worked with optical satellite imagery knows how tricky clouds might be. Misclassified cloud pixels might propagate to downstream applications related to Earth surface monitoring (e.g. calculating NDVI). On the other hand, over-detecting clouds may lead to the loss of potentially valuable data. Therefore, masking out clouds accurately is an essential step of optical imagery preprocessing.

Although many rule-based cloud masks are available, they often tend to misclassify clouds and cloud shadows and are computationally expensive.
Last year KappaZeta released KappaMask, an AI-based cloud masking processor for Sentinel-2. It was designed specifically for the Northern European terrestrial summer conditions and used U-Net as a cloud detector. You can read more here: https://www.mdpi.com/2072-4292/13/20/4100
KappaMask’s impressive performance motivated its further development. We aimed to expand it to global conditions. That took quite a while but here it is (drumroll…) KappaMaskv2.
In this blog post, we will guide you through the process of KappaMaskv2 development, including dataset compilation, model training, and the most exciting, performance results.
KappaMaskv2 overall flow
KappaMaskv2 is designed for Sentinel-2 Level-1C products. It takes Sentinel-2 product and splits it into 484 non-overlapping sub-tiles of 512 x 512 pixels, where each band is resampled to 10 m resolution. Then, sub-tiles are passed to the cloud detector. The model’s output is a classification map that identifies each pixel as clear, cloud shadow, semi-transparent cloud, cloud, or missing class. As this classification is done separately for each sub-tile, it is followed by stitching all the classification masks into the original size of the entire product (10980 x 10980 pixels).

As the general overflow has stayed the same as in KappaMask, more details can be found here.
KappaSet development
KappaMaskv2 is an AI-based cloud and cloud shadow processor whose quality highly depends on the training dataset. There are only a few datasets publicly available. Therefore, KappaZeta went through deserts and oceans, mountains and rainforests to create the one and only, KappaSet, a novel and diverse cloud and cloud shadow dataset. Check out the dataset distribution in Figure 3.
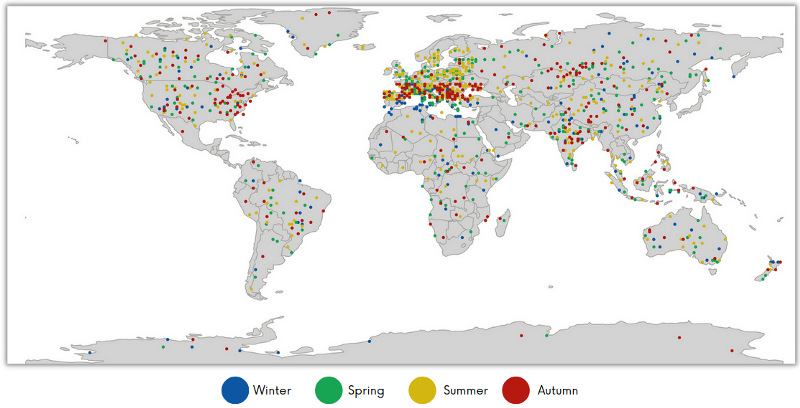
KappaSet’s main features include:
- Five classes: cloud, cloud shadow, semi-transparent clouds, clear, and missing.
- Different surface types : deserts, snow/ice cover, water bodies, cities, farmlands, mountains, rainforests.
- Different types of clouds: cumulus, cirrus, stratus.
- Various weather conditions
Moreover, KappaSet was generated using an active learning method, where sub-tiles with the most significant impact on the model performance were sorted out for labelling. It consists of 9251 labelled 512×512 sub-tiles, where 10% contain water bodies and around 7% include snow cover.
We genuinely hope KappaSet will benefit the research community and boost cloud masking development. KappaSet is available here: https://zenodo.org/record/7100327
Model architecture
The main improvement over the original KappaMask is the cloud detector architecture. We went from U-Net to DeepLabv3+. One might ask: why not use U-Net again if it was already accurate? First, it performed better on semi-transparent clouds. Secondly, it allowed us to reduce the size of our model which also reduced inference time.
DeepLabv3+ architecture allows to segment objects at different scales due to Spatial Pyramid Pooling. Also, using atrous convolutions is a great way to reduce the number of parameters while still making the field of view of convolutional filters larger. Thus, we went from almost 40 million parameters to 22 million.
We experimented with different backbones: ResNet-50, ResNet-101 and XCeption. XCeption performed the best and therefore was used as a feature extractor.
Model training
The loss function is the only modification to the training pipeline compared to the original KappaMask. Instead of Dice Similarity Coefficient loss (DSC), we used DSC++ loss (great article on it can be found here), which tackles calibration and overconfidence issues associated with DSC.
Performance results
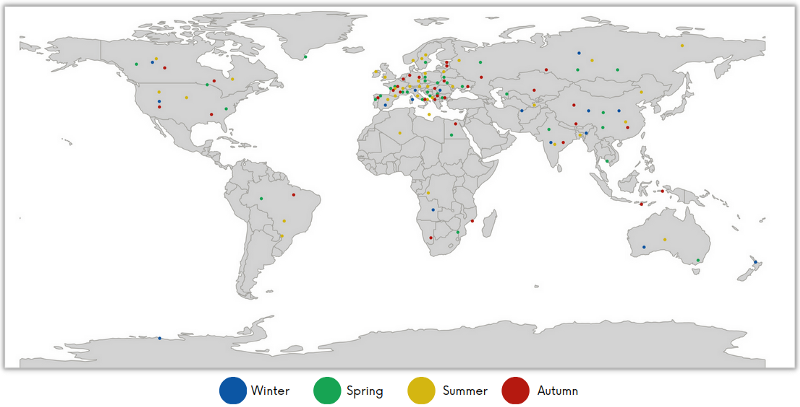
For a fair evaluation of any model, it is crucial to have a diverse and challenging test set. We ensured that the test set includes both similar and dissimilar sub-scenes seen in the training set. There are 803 sub-tiles in the test set. You can find its distribution in Figure 4.
KappaMaskv2 was compared to other cloud masking processors, including Sen2Cor, Fmask, MAJA, IdePix and S2Cloudless. In Figure 5, you can see that KappaMaskv2 generally performs better in every class. Fmask prediction is close to the KappaMask prediction, except for water being classified as a cloud. Sen2Cor and IdePix correctly identified cumulus clouds when cloud shadows and semi-transparent clouds are underestimated. Sen2Cor example shows that some semi-transparent clouds and cloud shadows are detected as missing class.
S2Cloudless prediction can be defined as “close to the ground truth label” if semi-transparent clouds and cloud shadows are considered. The general picture shows that clouds are overestimated. However, if the semi-transparent class is counted as a cloud, the prediction looks more accurate. MAJA prediction is similar to S2Cloudless, although some pixels are misclassified as clear.
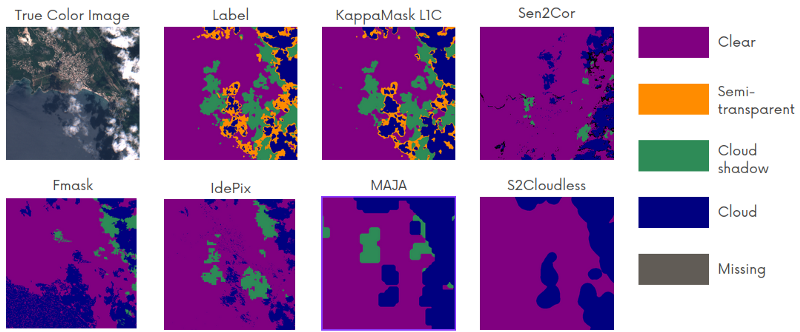
We used Dice Similarity Coefficient as an evaluation metric. Note that evaluation was performed on cloud, cloud shadow, semi-transparent cloud and clear classes.
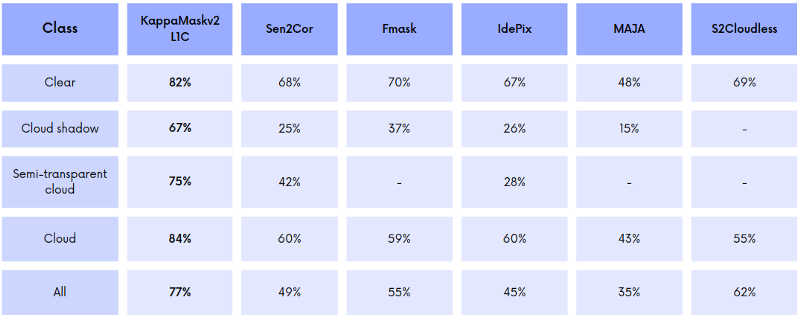
KappaMaskv2 L1C yielded the highest Dice coefficient for each class. The significant improvement of KappaMaskv2 L1C compared to other cloud masking approaches is more accurate cloud shadow and semi-transparent cloud detection with Dice coefficients of 67% and 75%, respectively. KappaMaskv2 L1C reached the Dice coefficient of 84% for cloud class, followed by IdePix and Sen2Cor with 60% each.
Running time comparison
As we mentioned before, changing cloud detector architecture allowed us to speed up the running time of KappaMaskv2. We compared how fast KappaMaskv2 was on both GPU and CPU in comparison to Sen2Cor, Fmask, IdePix, and S2Cloudless. MAJA is not presented as it was run in the backward mode meaning that the running time for MAJA depends on the number of valid products in the time series.

KappaMaskv2 with GPU is almost two times faster than Sen2Cor or Fmask and five times faster than IdePix. In turn, Sen2Cor is faster by 10 seconds compared to KappaMaskv2 if the latter uses CPU instead. In turn, S2Cloudless inference time is around 18 minutes which is 6 times slower than KappaMaskv2. KappaMaskv2 is available here: https://github.com/kappazeta/km_predict
Summary
- We compiled diverse cloud and cloud shadow dataset, named KappaSet. It consists of 9251 labelled sub-tiles at 10 m resolution, from Sentinel-2 Level-1C products. We believe that KappaSet will benefit the research on cloud masking. KappaSet can be found here.
- We presented KappaMaskv2, an AI-based cloud and cloud shadow processor for Sentinel-2, which operates at the global scale. It was compared to other cloud masking approaches on the carefully selected test set. The results showed that KappaMaskv2 significantly improved cloud shadow and semi-transparent cloud detection. KappaMaskv2 is available here. Feel free to try it out and share your experience with us!
Acknowledgements
We want to thank European Space Agency (ESA) for supporting, advising, and funding the project.